
Most leaders I talk to have the same unspoken frustration with AI. They’ve bought the licences. The team is drafting reports and proposals in seconds. On paper, productivity is up.
In practice, a hidden bottleneck has appeared. I call it the Double-Checking Tax.
Generic “wrapper” AI — a chat box wrapped around a general-purpose model — produces a plausible draft in thirty seconds. But because it’s working from general training rather than your actual documents, someone senior then spends two hours checking every name, number, and claim against the source files to make sure it didn’t invent something.
The time you saved drafting, you lose verifying. You haven’t bought efficiency. You’ve just moved the manual work downstream.
We stopped talking about our technology and measured the thing that actually matters: how good are the answers, really?
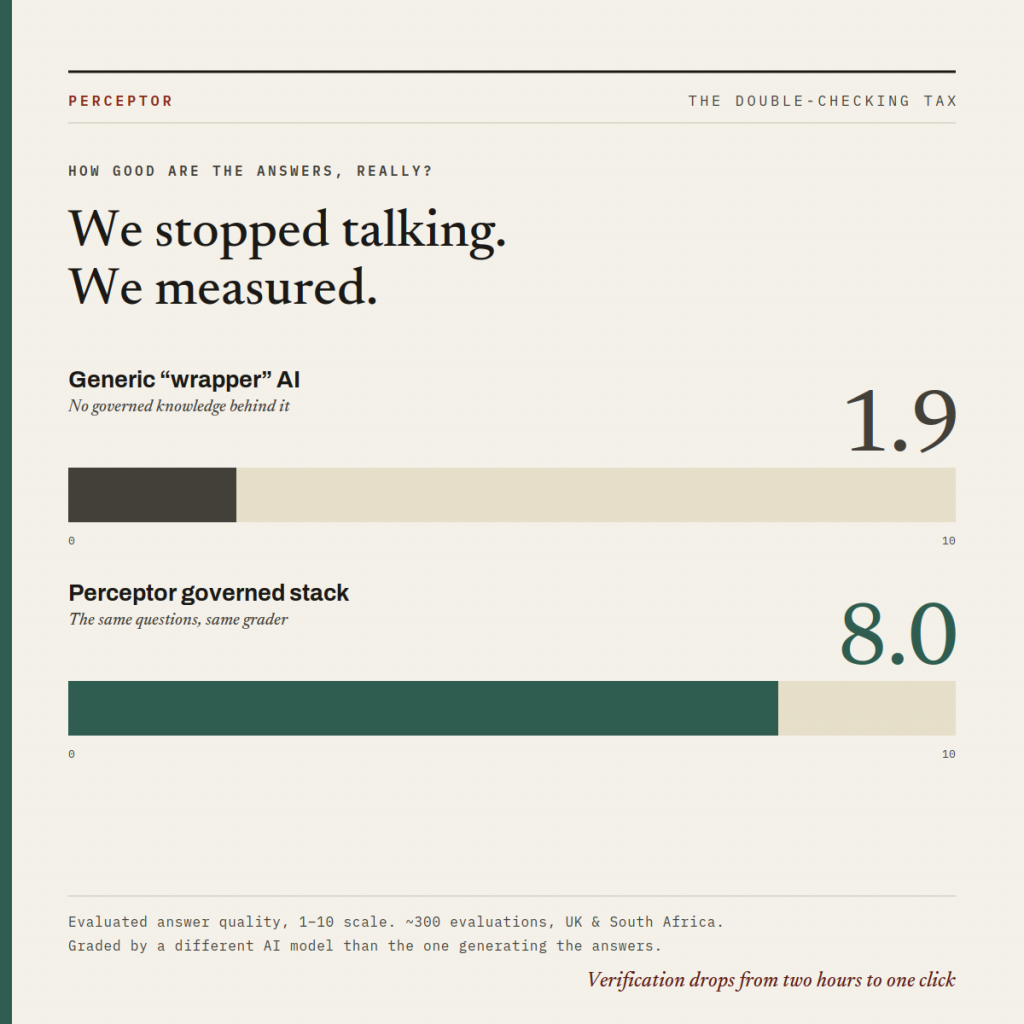
We ran nearly 300 evaluations across client organisations in the UK and South Africa. Crucially, the answers were graded by a different AI model than the one that generated them — so the marker isn’t grading its own homework. Each answer was scored on four dimensions — relevance, strategic alignment, context awareness, and actionability — on a scale of one to ten.
- A general model, asked our clients’ real strategic questions with no governed knowledge behind it, averaged 1.9 out of 10. It occasionally landed a relevant point by luck, but was essentially blind on strategy and context — the two things that matter most when you have to make a decision.
- The same questions, run through Perceptor’s governed knowledge stack, scored 8.0 out of 10. And that average includes our earliest runs, before we’d tuned anything. It’s an operational floor, not a highlight reel.
Here’s the part I didn’t expect.
We also tested our own framework — our clever prompting layer — without the governed knowledge underneath it.
It barely moved the needle.
That’s an uncomfortable lesson for much of the AI market: the value was never in better prompts. It’s in governed, organisation-specific knowledge the model can actually stand on.
And we made it checkable. Every answer Perceptor gives links straight back to the exact sentence in the exact source document it came from. If you want to verify a claim, you click it — you don’t re-read the file.
That audit trail isn’t a compliance burden bolted on the side; it’s what dissolves the Double-Checking Tax. Verification goes from two hours to one click.
Start Small, Scale Fast
You don’t need a six-month data clean-up to get there. We start with your fifteen best source documents and a short conversation about your priorities, in a walled-off space where your data is never used to train anyone’s model. Small footprint, fast start.
If your team is tired of double-checking AI drafts and you’d like to see what auditable quality actually looks like, drop a comment or DM me and I’ll send over our short SME Operational Briefing.
Sven Thiele — Founder & CEO, MangoMoon Perceptor